业务指标多维分析算法盘点
发布时间:2020-03-05 16:55:00
KPI指标(如网页访问量,交易量,失败量,响应时间等)与多维属性(如源系统、交易类型、交易渠道等),是金融、互联网等行业常见而重要的业务监测指标。当一个 KPI 的总体值发生异常时,想要解除异常,定位出其根因所在的位置是关键一步。然而,这一步常常是充满挑战的,尤其当根因是多个维度属性值的组合时。
我们先举一个简单的例子说明业务指标多维分析的问题:
我们先举一个简单的例子说明业务指标多维分析的问题:
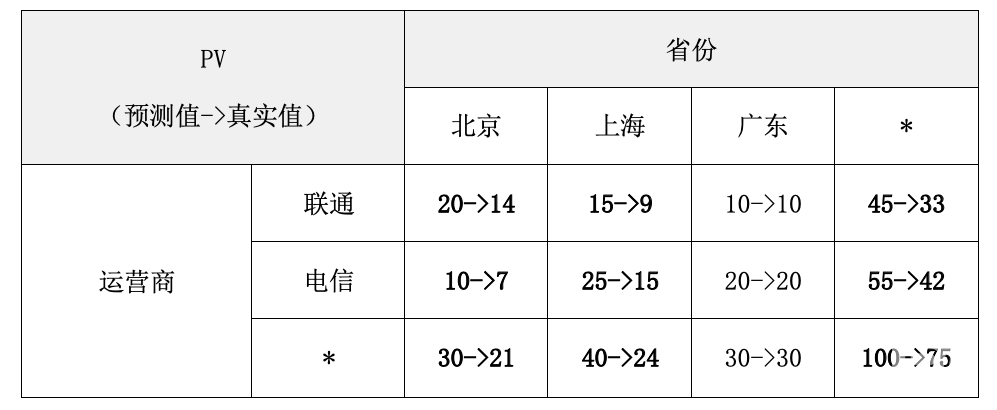
上表是某网站的PV来源明细(虚构)
从整体来看,该网站的实际PV(访问量)比预期要低;从明细来看应该是北京和上海的PV异常,与运营商无关。我们希望多维分析算法能够自动帮我们定位到是北京和上海的问题。
在实际的场景中,主要困难和挑战有以下两个方面。首先,不同的组合的KPI是相互依赖和影响的,真正的根因元素的KPI异常,可导致其他元素的KPI也发生变化,很难对影响KPI指标的根因做一个量化的判断。第二,由于KPI拥有多维度的属性,因此随着维度的增加或粒度的细化,元素的数目往往呈现指数级增长的趋势,可能需要从成千上万的多维属性空间进行搜索;此外,对如此多的维度快速做预测也是一个挑战。
下面为大家盘点一下与多维定位相关的5个具有代表性的算法(文献)原理、针对场景、优劣、落地性等:
- Adtributor: Revenue Debugging in Advertising Systems
- iDice: Problem Identification for Emerging Issues
- HotSpot: Anomaly Localization for Additive KPIs with Multi-Dimensional Attributes
- Squeeze:Generic and Robust Localization of Multi-Dimensional Root Causes
- 必示业务明细多维定位算法
1、Adtributor: Revenue Debugging in Advertising Systems
简介:Adtributor假设所有根因都是一维的,提出了解释力(Explanatory power)和惊奇性(Surprise)来量化根因的定义。使用ARMA模型对KPI进行预测,通过计算维度的惊奇性(维度内所有元素惊奇性之和)对维度进行排序,确定根因所在的维度(例如省份)。在维度内部计算每个元素的解释力,当元素的解释力之和(例如北京+上海)超过阈值时,这些元素就被认为是根因。
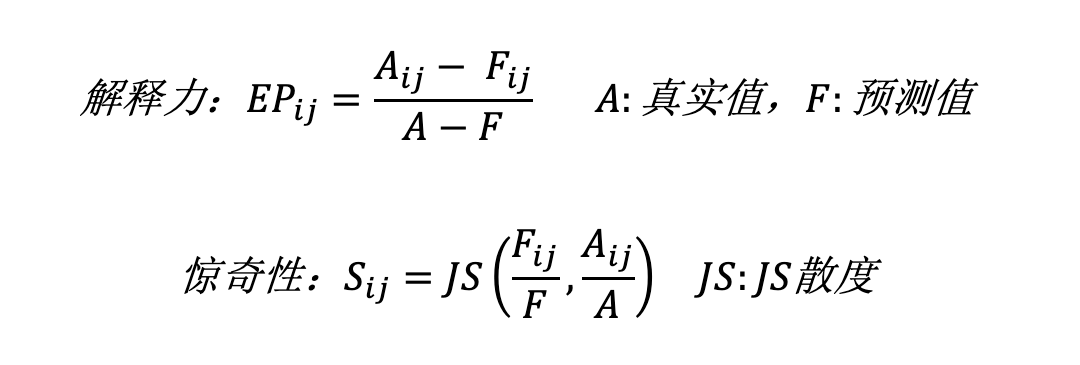
上述是针对基本类型的KPI的计算公式(例如PV、交易量),对于派生类型的KPI(多个基本类型KPI计算得到,例如成功率)就不太适用了。当然,作者也提出了另一套公式来计算派生型KPI,主要是让“解释力”和“惊奇性”的分数符合我们对于异常的“直觉”。
评价:Adtributor提出的“解释力”和“惊奇性”对根因给出了量化的评价,有很强的借鉴意义。将根因限定在一维的假设也极大的简化了问题的复杂度。但是这样的假设并不太符合我们的实际场景,同时用解释性和惊奇性的大小来衡量根因也不完全合理。因为其没有考虑到维度之间的相互影响以及「外部根因」的可能,即根因所在的维度没有在数据中体现。另外,Adtributor的根因分析严重依赖于整体KPI的变化情况,对于整体变化不大,但是内部波动较为剧烈的数据表现不好。
总的来说,Adtributor是一种可以落地的业务指标明细多维分析算法,能够提供一些对排障有帮助的信息,配合人工筛查,可以有一定的效果。但是如果应对更多的维度、更复杂的情况,甚至存在外部根因的时候,能够提供的帮助就有限了。
2、 iDice: Problem Identification for Emerging Issues
简介:iDice针对的场景和Adtributor稍有不同,它分析的数据是一段时间序列下的多维明细数据而不是对某一个具体的时间点。首先它认为根因的表现是一定在时间序列上体现突变,然后根据信息熵的思想提出Isolation Power的概念来解释根因,基本的思想就是对每一个维度组合计算他们的Isolation Power值,一个有效的根因维度组合(图1 Effective Combination)是其IP值大于其所有的直接子节点和直接父节点。在判断了当前节点为「可能的根因」后,其所有子节点都被剪枝掉。为了降低搜索和聚合的复杂度,本文还提出了多种剪枝方法。如减掉数量较小的节点、减掉在时间序列上没有突变的的节点等。最终对每个「可能的根因」突变点前后计算类似Adtributor的“惊奇性”进行排序。

图1:图中的每一个节点代表一个维度组合,虚线部分圈住的节点是Effective Combination节点的所有子节点
评价:iDice提出了一种更符合实际情况的根因评估指标:Isolation Power,利用多种剪枝手段减少搜索的复杂度。利用了数据的时间序列,从一定程度上缓解了单一时间点做预测时不准的情况。但是对大量的节点做异常检测也带来了额外的复杂度,在维度和取值较多时,上层节点的数目要远远大于叶子结点的数目。从上至下的搜索以及至下而上的聚合的复杂度极大,虽然本文提出了几种剪枝方法,但是并不能带来量级上的减少。
同时,iDice的几种剪枝略显暴力,例如基于Impact的剪枝,虽然减掉的是量较少的维度组合,但是当维度和取值增加,极限情况下每一个叶子结点的维度组合的量只有1,这样剪枝的结果是不可以接受的。另外iDice对于派生类型的指标没有很好的处理方法,例如成功率,首先剪枝不能很好地进行,其次做变点检测时,容易忽略掉真正的“根因”。
3. HotSpot: Anomaly Localization for Additive KPIs with Multi-Dimensional Attributes
简介:HotSpot和Adtributor一样使用“预测+搜索”的策略,针对基本类型的指标(可加型,例如交易量,PV等)提出了基于Ripple Effect的根因判断方法,即维度组合与其子节点之间越满足Ripple Effect条件就越有可能是根因,提出了Potential Score来量化一个节点与其所有叶子结点之间满足Ripple Effect程度。举个简单的例子,例如表一中的北京。PV从30->21,而北京联通和北京电信分别从20->14、10->7,变化的比例和北京相同(Ripple Effect),所以判断出北京是根因。和iDice对于根因集的定义不同,HotSpot会考虑同一维度下的根因组合,例如不仅有(北京,联通)这样的元素,还会有(北京,上海)这样的元素。这样当然会带来额外的搜索复杂度(2n-1,n是维度取值数目之和),所以作者提出基于MCTS(蒙特卡洛树搜索)和分层的剪枝策略,按照获得最大Potential Score收益的路径进行搜索,如果某一元素的PS分数较低,则减掉其子节点(Hierarchical Pruning)。
评价:HotSpot提出具有启发意义的根因判断方式:Ripple Effect。使用叶子结点而不使用直接子节点参与Potential Score的计算,达到了边搜索边聚合的效果,极大的降低了空间的使用。创新的将MCTS应用到搜索的剪枝中,降低了搜索的复杂度。当然,HotSpot也存在一些局限,例如假设所有的根因在一个Cuboid内(完全相同的维度组成:eg.C省份、C省份、运营商)、没有考虑到非可加型指标(eg.成功率)、时间序列预测方法也只是使用了简单的MA,如果指标有一定的波动,可能会影响PS的准确性。另外使用叶子结点计算PS虽然减少了空间的使用,但是随着维度和取值的增加,叶子结点的量下降,极端情况下下降到1,此时的PS计算会受到较大的影响。
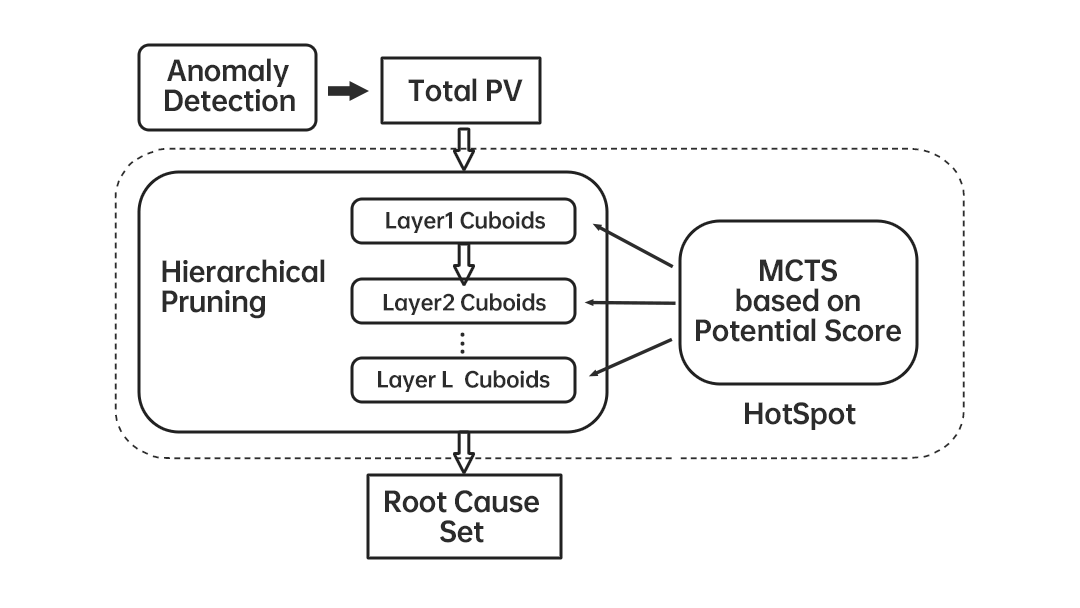
图2:HotSpot算法流程
4. Squeeze:Generic and Robust Localization of Multi-Dimensional Root Causes
简介:Squeeze在HotSpot的基础上提出广义的Ripple Effect,证明RE不仅仅适用于基本类型的指标,也适用于派生类型的指标(eg.成功率)同时解决了0值预测的问题。和之前的算法搜索策略不同,Squeeze先至下而上剪掉正常的叶子结点的减小搜索空间,然后计算叶子结点的deviation score来进行聚类,因为根据RE,相同的根因的叶子结点将具有相似的deviation score。然后自顶向下在每一个簇中搜索根因。Squeeze假设每一个簇中的根因都在一个Cuboid(见HotSpot简介)内,同样提出类似于Potential Score的GPS来作为是否是根因的量化标准。
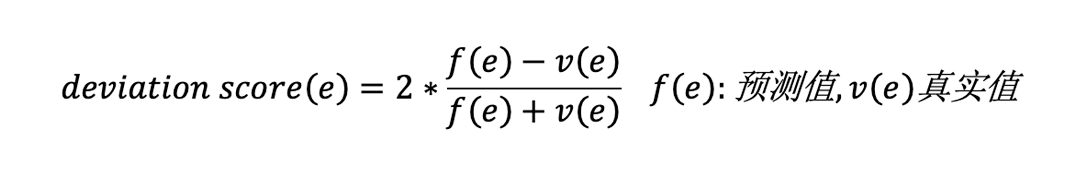
图3:Squeeze算法流程
评价:Squeeze在HotSpot的基础上进行了理论的拓展,增加了算法的通用性和鲁棒性。“Squeeze”的做法也极具创新性。不过实际的业务场景可能会对算法的准确性产生一定的影响,例如预测不准可能会导致聚类不准确、同时有多个异常或者外部异常也会影响聚类效果。另外按照GPS对结果根因进行排序有时也不符合真实业务场景,因为真实的业务场景数量的大小同样是一个重要的衡量指标。失败量从50到100的组合可能比0到5的组合更值得注意。
5. 必示AIOps业务明细多维定位算法
简介:必示「业务明细多维定位算法」采用“异常检测+搜索”的策略,依托于必示「指标异常检测」算法,在指标异常检测算法产生告警之后触发分析,业务场景比较明确。算法场景中大部分都是多指标同时异常的情况,所以必示提出基于“影响力”的异常检测算法,简单来说就是衡量每个维度组合对整体指标变化(异常)的影响程度,是一种与指标含义无关的异常检测方法。在搜索方面,必示采用了一套可伸缩的搜索方案,在时间效率和空间效率上灵活切换,以适应不同规模大小的数据。必示AIOps业务明细多维定位在核心算法给出结果之后,利用数据的特性、根因集中数据的相似性等对结果进行进一步的处理,能够给出更多的利于排障的信息。
评价:更符合真实的业务场景——没有过于强烈和不切实际的假设,没有做暴力的剪枝手段。对于结果也不仅仅是简单依据奥多姆剃刀原则保留最简洁的那一个,必示AIOps根据业务的需求提供信息量最大的结果。
提出基于“影响力”的统一异常检测手段——之前的算法对于多KPI的支持并不好,Adtributor和Squeeze虽然可以对派生指标进行根因定位,但是并不能做到跨指标的根因排序。
更完善的多维定位方案——Adtributor、HotSpot、Squeeze都假设预测准确,只使用了简单的预测方法。实际上,如何快速而准确的对大量的明细数据做预测|异常检测也是一个极大的挑战。
可伸缩的搜索方案——在实际的应用场景中,维度变化、取值数量变化以及数据组成变化都会影响资源的使用,因为我们的异常分数可加和的特性,使得我们的算法可以在先聚合后搜索和边聚合边搜索之间灵活的适配。
更稳定的根因衡量标准——必示AIOps借鉴了Isolation Power的计算以及Ripple Effect的条件,提出了不受多维度组合异常和外部根因影响的根因衡量标准。
智能的结果合并——对于最终的结果,必示AIOps不仅按照他们的分数大小进行排序,还会根据他们之间数据的相似性和结点关系作出智能的结果合并,以求给出更准确、精细的利于排障的信息。




