AIOps挑战赛 | 2020 AIOps挑战赛赛题解读
发布时间:2020-03-26 18:20:00

本次AIOps挑战赛主要是针对微服务系统进行故障检测和根因定位
一、挑战赛背景详细介绍
二、挑战赛题目介绍
三、数据解读及如何利用数据
四、挑战赛评估:预赛、复赛评估机制
一、挑战赛背景
当前的云环境,包括企业的ID系统在向云原生的方向发展。云原生涉及到几项使能技术,包括容器、服务网格(service mesh)、微服务(microservices)以及可变基础设施等。这些都是重要的使能技术,这些技术对于我们做DevOps是非常大的优势,同时也带来一些挑战。对于运维来讲,其中最大的挑战即在于系统规模和复杂度。整体的架构越灵活,对于运维的挑战就越大。当我们走向FaaS(Function as a Service)后,对于云的挑战将更大,大家面临的压力也会更大。这时我们需要一些更加智能和自动化的工具来辅助完成运维工作。
做SRE或企业IT运维工作中经常会遇到的简单问题(如内存泄漏、程序bug、数据竞争等)以及一些外部环境影响(配置变化、网络因素、应用程序之间的相互干扰以及资源使用的异常等)都可能会对系统造成比较大的影响。轻则影响性能,重则导致失效、宕机等。大家可以看到,这些故障报告变得越来越司空见惯。而在云环境中发生这些故障,影响面是非常大的。
我们做故障检测,是在检测怎样的故障?云系统内有什么类型的故障?我们根据一些学术论文和开放数据集做了简单调研和汇总。在这个总结中,我们把故障做了一个大体分类,如配置故障、硬件失效、与时间相关的故障、过载,以及软件发布过程中由更新引入的bug等等。针对这些问题我们应该如何解决?本次挑战赛的意图之一,即是针对云环境中的这些问题,找到更好的检测和根因定位方法。
当一个软件发生问题,往往会直接影响用户体验。此时我们需对系统进行诊断,找到问题的根因。传统运维中,我们往往会用一些人肉的方式,手动检测、逐一排查、跨部门寻找问题,整个过程非常复杂。从检测到恢复再到恢复策略执行,流程和时间都是比较长的。我们是否可以将MTTR(Mean Time to Repair)由小时级别缩短到分钟级,甚至是秒级别,这是运维人共同追求的愿景。
AIOps这个概念对我们来讲已经不陌生了——它是一个端到端的解决方案。AIOps利用大数据、机器学习等技术,帮助我们从IT运维数据中挖掘一些深度的洞察,从而实现诸如自动系统恢复、检测等一系列行为,使系统更加可靠。使用AIOps来解决实际IT系统问题时,在不同场景中,我们可能面临大量挑战。本次我们主要讨论原生云中的挑战。
原生云中软件一般采用微服务架构,软件配置松散、数量多,软件架构和依赖关系十分复杂。
目前我们的软件发布大多采用DevOps形式,即连续地开发与集成,在此过程中开发和运行环境都很难处于稳定状态。这种不稳定环境对于运维是一个挑战,对AIOps也是一个很大的挑战:很难找到一个稳定的模型或算法来解决问题,算法需要不断适应环境的变化。
软件的规模越来越大往往会导致过量使用监控。软件运行过程中产生大量指标,监控设备可能采集大量冗余数据,让我们很难判断哪一个指标是有效的。对AIOps,这是来自数据的一个挑战。
二、挑战赛题目讲解
本次挑战赛的题目是“微服务应用系统故障发现和根因定位”。我们将提供真实生产环境的一个微服务系统,收集系统运行时的运维数据,可能包含如调用链数据、业务环境指标、操作系统、中间件、数据库、容器等性能指标。同时我们也会提供一个系统部署结构图。静态拓扑图本次没有提供给大家,大家可以通过调用链做还原。这是我们提供的数据源。
目前我们已经公布了一部分数据,大家可以在官网下载 (http://iops.ai) 在此补充一个说明:在公布的数据基础上,我们会公布故障类型的全集。本次比赛中主要故障类型基本包含:容器CPU利用率类型故障、容器内存利用率类型故障、数据库类型故障、主机网络类型故障、容器网络类型故障等。
关于定位粒度——除网络类型的故障外(注:由于目前提供的数据有限,对于网络类型故障可能来不及采集指标),上述类型故障均需定位到性能指标。这里的性能指标并非指环境指标,而是指操作系统性能指标、容器性能指标或中间件性能指标。以上是关于本次赛题以及定位粒度的解读。
我准备了一张图来帮助大家理解题目(如下图)。这是一个示例,并非浙江移动的真实架构。大家可以看到微服务系统是跑在容器里,容器与主机之间有关系;一个主机可以跑多个容器。在此次赛题中,也牵扯到这样的实体。
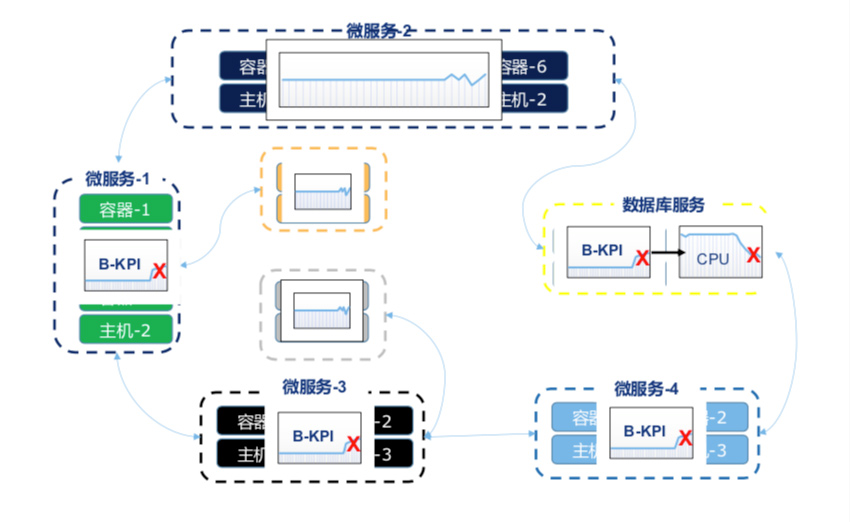
举一个例子——假设一个微服务系统的拓扑结构和依赖关系如上图所示,大家在解题时需要做根因定位。一般情况下(这里不做特殊要求),我们首先要观察业务指标是否有异常;如有异常,即进入排查和定位阶段。在此我们首先看到入口服务业务指标发生异常,接下来需要不断向下搜索排查与其相依赖的指标,如确定到某个微服务后继续向下排查,定位到数据库故障。在此需要说明的是,“定位到数据库故障”并没有完成赛题,我们希望大家再向下一层做进一步的根因定位,在“指标”这一层定位到故障的根因。
三、数据解读及如何利用数据
到目前,大赛已经发布了几个G的数据。首先我们来看一下这些数据的含义,从数据类型来看,预赛、复赛、决赛会有一些不同。
三、数据解读及如何利用数据
到目前,大赛已经发布了几个G的数据。首先我们来看一下这些数据的含义,从数据类型来看,预赛、复赛、决赛会有一些不同。
- 预赛阶段,主要提供离线数据,以.csv格式交给选手。选手可以直接利用csv数据进行分析
- 复赛阶段,采用实时数据。数据不再离线交给选手,而需要大家实时通过Kafka读取数据、消费数据,进行异常检测。
- 决赛阶段,采取现场答辩形式。(具体流程请关注后续温希道博士分享内容推送)
目前大家拿到的数据大致分为以下几个类别:
- 业务指标:对应“aiops-esb”文件;
- 调用链数据:6个文件;
- 容器指标:关键指标,赛题需定位到容器内的具体性能指标;
- 中间件指标:记录微服务以外的,如MQ和Redis等类型的组件指标;
- 主机指标:抓取的主机操作系统相关的操作指标;
- 数据库指标:Oracle相关的指标类型;
- 部署文档:应用架构清单,反映部署时如何应对。如,某微服务有几个实例,分别对应的容器。
业务指标
业务指标记录系统关键的入口服务,如图中“osb_001”。其中时间戳部分,是采用Linux时间戳,不同指标采样周期是不一样的,所采用的Linux时间戳也有不同:有些是秒级的,有些是毫秒级的——这是需要大家注意的一点。比如在业务指标中,是60秒的一个采样(大家可以计算出来的)。业务指标中比较重要的是平均响应延迟、平均时间、业务量、成功率、成功数量、非成功率等等。关于业务指标,大家需要依托此文件做故障检测。
容器指标
• “itemid”:是对某一个指标的标识,具有唯一性;
• “name”:指标名;
• “timestamp”:不同文件的时间戳略有不同,如容器指标的时间戳是毫秒级别的,这意味着大家在换算时是需要除以1000的,这一点需要大家在处理时注意一下。
• “omdb_id”:容器ID
中间件指标,包含Redis和MQ
• “name”:关于指标名意义的理解,对于比赛的影响不是很大
• “timestamp”:注意事项如上,在此不赘述
• “omdb_id”:代表具体Redis实例
主机指标
如下图所示,主机指标与中间件指标十分类似,同样需要注意采样周期,在此不赘述。

数据库指标
“Asm_Free”:关于Oracle_db的重要参数,主要记录某文件的存储空间,可用于根因定位,尤其是发生数据库故障时,很可能要用到。
调用链数据格式解读及使用方法
调用链最早出现是在谷歌2010年发布的一篇技术报告,在Dapper系统中首先提出如何进行一个端对端的、全链路的请求追踪,在此基础之上也衍生了很多优秀的开源软件。
需要请大家注意的是,此次赛题发布的调用链中Trace ID一定要关联一个完整的调用过程。每一个Trace ID会产生很多Span ID,请求执行过程中每发生一次RPC会产生一个Span ID,这个Span ID与其上一级的Span ID有“父子关系”(即调用关系)。一个完整的Trace由多个Span构成,这些Trace或Span ID会散布在几个文件中。选手需要将这些文件汇总或整合,从中获取一个完整的Trace(或请求路径)。
以下图为例,将调用链数据格式中几个重要属性为大家做一下解读
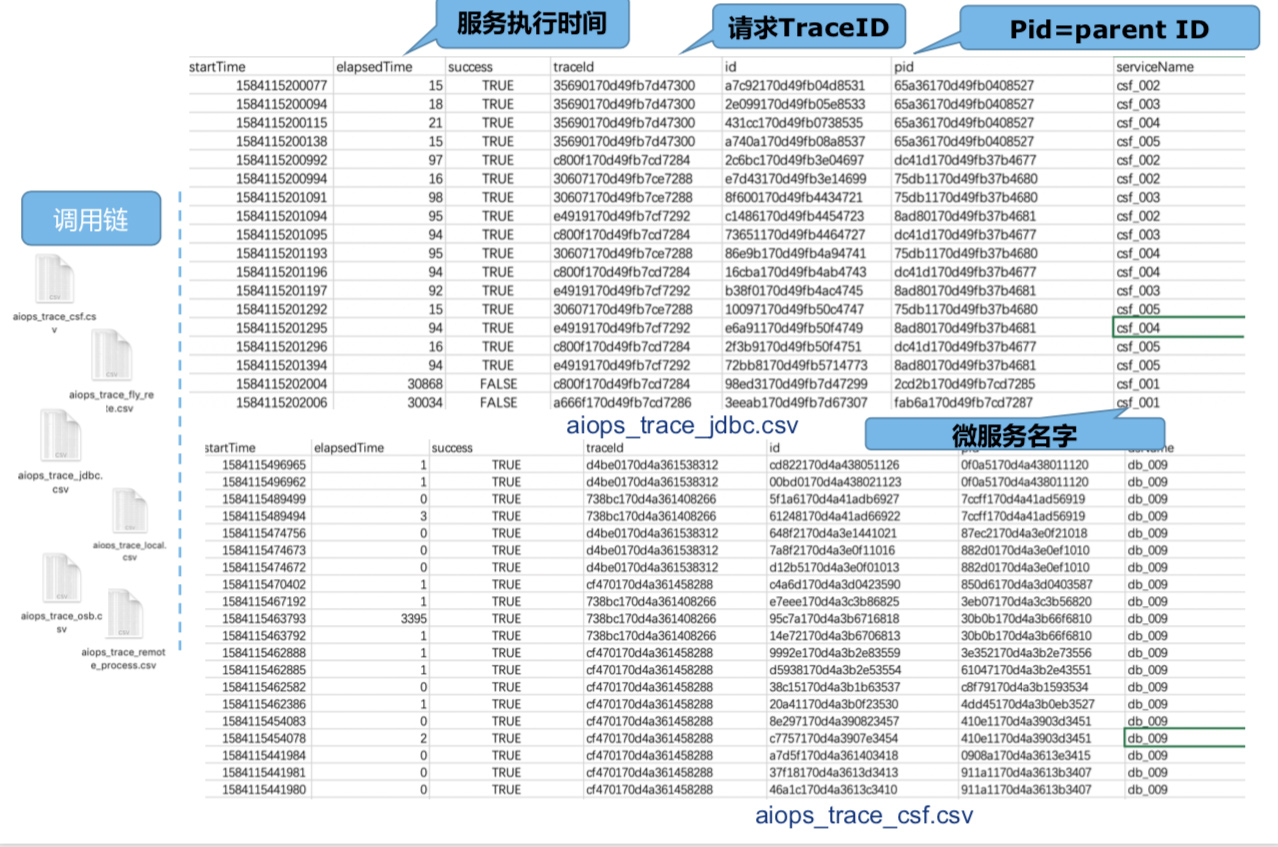
- “startTime”:Trace或Span生成的时间;
- “elapsedTime”:服务执行时间;
- “success”:请求是否成功;
- “traceId”:即上文中提到的Trace ID,需要依此提炼出一条完整的Trace路径,此Trace ID是唯一的。
- “id”:指Span ID
- “pid”:即Parent ID,指Span ID父子关系中的“父Span ID”;id与pid之间存在父子关系,可以通过这种父子关系将请求执行的上下文关联起来——这是一条比较重要的规则。
- “serviceName”:对应在请求执行过程中具体执行的服务,即微服务的名字。
- 微服务中一个请求链路的最后一步是Database,这一点请大家关注文件中的说明。关于调用链数据的格式简单解读到这里。
以下图为例,来介绍一下数据用法

首先选手需要将Trace文件汇总整理(如图中“Trace-demo”),在Trace ID之下是与其相关联、相依赖的一系列Span ID。据此我们可以得到服务处理时间(如图中elapsedTime)或微服务业务指标,同时可获得服务之间的依赖关系(如图中“服务依赖图”),即服务与服务间如何请求指导。
调用链利用方式,简单为大家介绍到这里,在具体处理时会遇到一些问题,这些问题不会对根因定位产生太大影响。
部署文档
本次赛题对故障定位粒度的要求是定位到容器和指标,而利用调用链定位到服务不能完全满足赛题要求。通过部署文档可以看到定位到的服务所对应的容器,通过此对应关系进一步向下完成根因定位。在此做一个重要说明:文档内涉及到的两种类型的应用(如图中app1、app2)分别对应5种微服务(如图中csf_001~csf_005)。每一种应用程序,由多个容器实例运行。如:
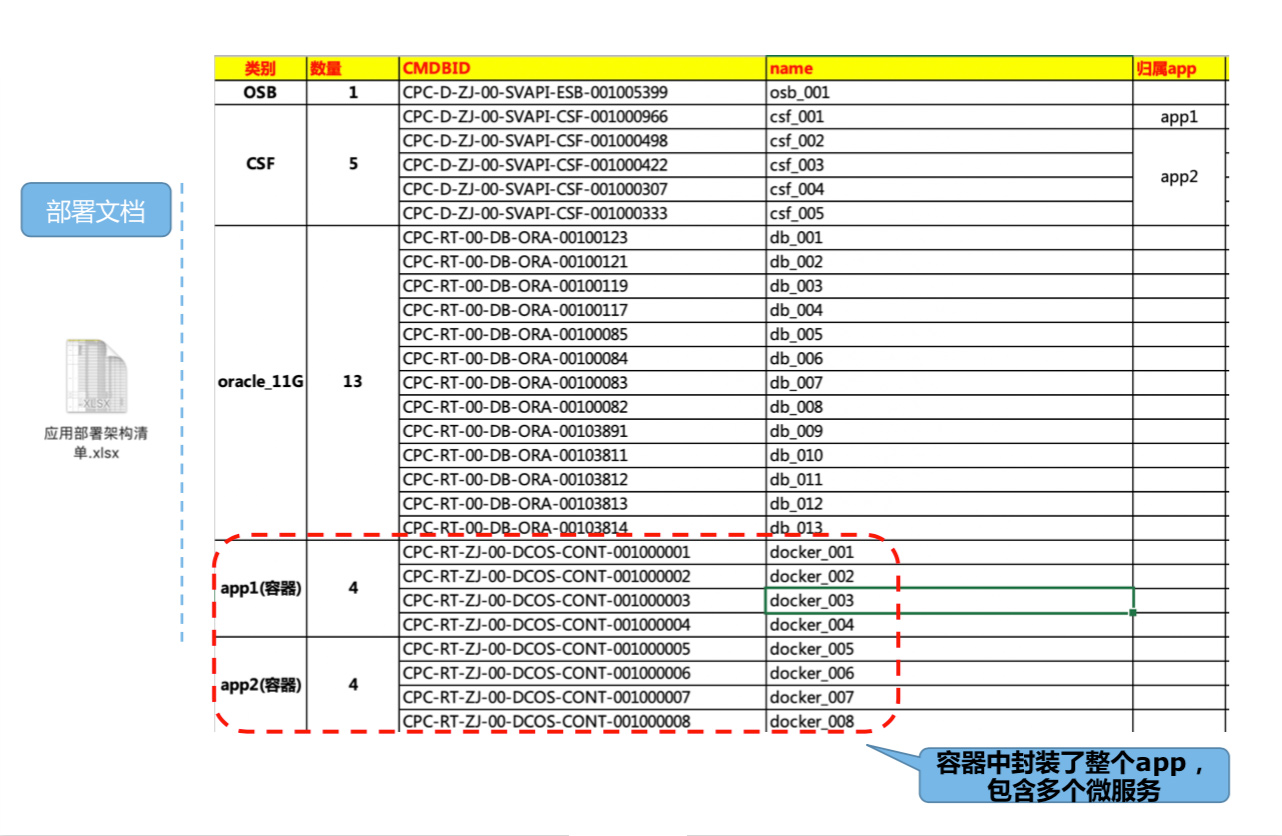
图中app1在docker_001~docker_004这4个容器实例中运行。
图中app2是由微服务csf_002~csf_005构成,打包后在docker_005~docker_008,4个容器中运行,那么此时docker_005中即包含了4个微服务——这一点是需要选手们重点关注一下的。
四、挑战赛评估
预赛评估标准:
- 预赛期间发布包含故障的离线数据,以及故障种类的全集,主要是CPU类型,内存类型,数据库和网络类型的故障。为了简化这次预赛的题目,在提供数据的同时会标注故障注入的时刻、持续时长,及少量故障根因结果。
- 任意时刻最多只有一个故障。如出现多个故障,或不确定性故障也不必慌张。在预赛阶段只进行故障根因定位,不做故障的检测。
- CPU类型,内存类型,数据库和网络类型的故障默认粒度为“性能指标”。选手需要定位到故障发生的容器或节点,指出具体性能指标。网络类型的故障定位到故障发生的容器或节点即可。
- 对于每一个故障,参赛选手最多可推荐两个候选根因,并做出先后排序。排在第一位的根因正确得1分,排在第二位的根因正确得0.2分。没有正确答案得0分。如果定位的根因粒度不在性能指标的层面,除了网络类型的故障也是只能得0分。参赛选手最终得分的均值乘以100,就是最终分数。
复赛评估标准:
- 大赛使用的微服务场景在复赛阶段不会有变化。数据发布的形式由离线数据变更为实时发布离线真实运维数据。参赛选手可以通过Kafka获取实时数据。
- 主办方公布故障种类的全集,但是不提供故障发生点和故障的数量(即可能同一时刻会有多个故障)。参赛选手需要进行故障检测和根因定位。最终根据结果综合考量参赛选手故障检测的算法和根因定位的算法。
- 定位粒度与初赛要求一致。即CPU类型,内存类型,数据库和网络类型的故障默认粒度为“性能指标”。
- 具体评分规则待定,请关注组委会后续通知。
复赛阶段,选手需要实时消费大赛发布的数据,因此可将程序或算法部署到大赛提供的公有云环境当中,同时从公有云上的Kafka中实时获取和消费数据,进行根因定位。
★赛题组委会拥有评分规则的最终解释权。
★赛题组委会拥有评分规则的最终解释权。




